
인트로

최근 주니어 백엔드 개발자가 반드시 알아야 할 실무 지식을 읽으면서
DB 성능과 인덱스에 대한 내용을 다시 정리하게 됐다.
처음에는 DB 성능 문제가 생기면 “인덱스를 추가하면 되지 않을까?”라고 단순하게 생각했다.
하지만 책을 읽고 실무 상황에 대입해보니, 인덱스는 정답이라기보다
조회 패턴에 맞춰 설계해야 하는 도구에 가까웠다.
특히 풀스캔, LIKE 검색, COUNT, 정규화와 비정규화,
오래된 데이터 분리, 캐시, 장비 확장은 각각 따로 떨어진 주제가 아니었다.
결국 하나의 질문으로 이어졌다.
지금 이 API는 DB에서 읽을 필요가 있는 데이터만 읽고 있는가?
이번 글은 풀스캔을 줄이기 위해 내가 먼저 확인해야 할
DB 성능 항목 9가지를 정리한 기록이다.
특정 회사 시스템을 그대로 설명한 글은 아니고,
실무에서 자주 만나는 조회 API를 기준으로 재구성한 예시다.
수집 대상
이 글은 ORM이나 SQL 매퍼 사용법보다는
순수 DB 레벨에서 조회 성능을 떨어뜨리는 패턴과 대응 기준을 정리한 글이다.
내가 특히 기억해두려는 항목은 아래 9가지다.
| 번호 | 항목 | 먼저 볼 질문 |
|---|---|---|
| 1 | 풀스캔 | 실행 계획에서 읽는 row가 과하게 많지 않은가 |
| 2 | 단일 인덱스와 복합 인덱스 | 조회 조건이 어떤 컬럼 조합으로 반복되는가 |
| 3 | LIKE 검색 |
일반 인덱스로 처리할 검색인가, 전문 검색이 필요한가 |
| 4 | 커버링 인덱스 | 테이블 row 접근 없이 인덱스만으로 끝낼 수 있는가 |
| 5 | 인덱스 개수 | 읽기 성능 때문에 쓰기 비용을 과하게 늘리고 있지 않은가 |
| 6 | 정규화와 비정규화 | 조인 비용과 정합성 비용 중 무엇이 더 큰가 |
| 7 | 시간 조건 | 기본 조회 범위가 너무 넓지 않은가 |
| 8 | COUNT 집계 |
전체 개수가 정말 필요한가 |
| 9 | 데이터 분리, 캐시, 장비 확장 | 쿼리 튜닝 이후에도 구조적 한계가 남는가 |
개발환경
예시는 아래 환경을 기준으로 작성했다.
| 구분 | 내용 |
|---|---|
| 언어 | Java 17 |
| 프레임워크 | Spring Boot 3 계열 |
| DB | MySQL 8.x 기준 예시 |
| 조회 방식 | 게시글 목록, 검색, 상세 조회 |
| 확인 도구 | EXPLAIN, 실행 시간 로그, slow query log |
DBMS마다 옵티마이저와 인덱스 동작은 다를 수 있다.
그래서 이 글의 SQL은 개념을 설명하기 위한 예시이며, 실제 적용 전에는
반드시 운영 DB와 유사한 데이터 분포에서 실행 계획을 확인해야 한다.

문제 상황
게시글 목록 API가 있다고 가정한다.
처음에는 아래처럼 검색어, 상태, 작성 기간을 모두 받을 수 있는 API를 만들었다.
SELECT id, title, writer_name, status, created_at
FROM article
WHERE status = 'PUBLISHED'
AND title LIKE '%spring%'
AND created_at >= '2026-05-01 00:00:00'
ORDER BY created_at DESC
LIMIT 20 OFFSET 0;
기능만 보면 자연스러운 쿼리다. 하지만 데이터가 많아지면 문제가 생길 수 있다.
status나 created_at에 인덱스가 있어도 title LIKE '%spring%' 조건은
일반적인 B-Tree 인덱스로 효율적인 검색을 하기 어렵다.
앞에 %가 붙으면 문자열의 시작점을 알 수 없기 때문이다.
결국 DB는 많은 row를 읽고, 그중에서 조건에 맞는 데이터를 골라내야 할 수 있다.
이때 실행 계획에서 type=ALL이 보이면 전체 테이블을 훑는 풀 테이블 스캔 가능성을 의심해야 한다.

내가 처음 헷갈렸던 부분은
“컬럼에 인덱스가 있으면 무조건 빠르다”는 생각이었다.
하지만 인덱스가 있어도 조건 형태, 컬럼 순서, 조회 범위,
데이터 분포에 따라 옵티마이저는 인덱스를 쓰지 않을 수 있다.
1번째 시도: 검색 조건마다 인덱스 추가하기
가장 먼저 떠올린 방법은 조건에 등장하는 컬럼마다 인덱스를 추가하는 것이었다.
CREATE INDEX idx_article_status ON article(status);
CREATE INDEX idx_article_title ON article(title);
CREATE INDEX idx_article_created_at ON article(created_at);
겉으로 보면 괜찮아 보인다. WHERE에 등장하는 컬럼마다 인덱스가 있기 때문이다.
하지만 이 방식은 문제를 정확히 해결하지 못할 수 있다.
첫째, 단일 인덱스 여러 개가 항상 복합 인덱스 하나와 같은 효과를 내지는 않는다.
DB 옵티마이저가 index merge를 선택할 수도 있지만,
자주 실행되는 핵심 조회라면 조회 패턴에 맞춘 복합 인덱스가 더 명확할 때가 많다.
둘째, LIKE '%keyword%' 검색은 일반적인 B-Tree 인덱스와 잘 맞지 않는다.
LIKE 'spring%'처럼 앞부분이 고정된 검색은
범위 검색으로 인덱스를 활용할 가능성이 있지만,
%spring%처럼 앞뒤를 모두 열어둔 검색은 일반 인덱스로 시작 위치를 잡기 어렵다.
셋째, 인덱스가 많아질수록 쓰기 비용이 늘어난다.
INSERT, UPDATE, DELETE가 발생할 때 테이블 데이터뿐 아니라
인덱스도 함께 갱신해야 한다.
그래서 인덱스는 많이 만들수록 좋은 것이 아니라 필요한 만큼만 만들어야 한다.
예를 들어 이미 (status, created_at) 복합 인덱스가 있는데
status 단일 인덱스를 또 추가하는 경우를 생각할 수 있다.
MySQL에서는 복합 인덱스의 선행 컬럼을 활용할 수 있기 때문에 단일 인덱스가 중복일 수 있다.
물론 인덱스 크기, 조회 빈도, 옵티마이저 선택에 따라 예외가 있을 수 있으므로
실행 계획과 실제 사용량을 보고 판단해야 한다.
| 접근 | 장점 | 한계 |
|---|---|---|
| 조건 컬럼마다 단일 인덱스 추가 | 만들기 쉽다 | 실제 조회 패턴과 맞지 않을 수 있다 |
| 무조건 복합 인덱스 추가 | 특정 조회에는 빠를 수 있다 | 컬럼 순서가 틀리면 효과가 작다 |
전문 검색 없이 LIKE '%keyword%' 유지 |
구현이 단순하다 | 데이터가 많아지면 풀스캔 가능성이 커진다 |
이 시도에서 배운 점은 단순했다.
인덱스는 컬럼 기준이 아니라 조회 패턴 기준으로 설계해야 한다.
2번째 시도: 조회 패턴 기준으로 복합 인덱스 설계하기
다음으로는 실제 API가 어떤 방식으로 조회되는지 먼저 정리했다.
예를 들어 게시글 목록 조회의 핵심 패턴이 아래와 같다고 가정한다.
- 공개 상태의 게시글만 조회한다.
- 최신순으로 정렬한다.
- 대부분 최근 3개월 데이터만 조회한다.
- 한 페이지에 20개씩 가져온다.
이 경우에는 단순히 status, created_at 각각에 인덱스를 거는 것보다
아래처럼 자주 함께 쓰이는 조건과 정렬을 고려한 복합 인덱스를 검토할 수 있다.
CREATE INDEX idx_article_status_created_at
ON article(status, created_at DESC);
그리고 조회 쿼리도 범위를 제한한다.
SELECT id, title, writer_name, status, created_at
FROM article
WHERE status = 'PUBLISHED'
AND created_at >= '2026-02-01 00:00:00'
AND created_at < '2026-05-01 00:00:00'
ORDER BY created_at DESC
LIMIT 20;
복합 인덱스에서는 컬럼 순서가 중요하다.
MySQL 기준으로 (status, created_at) 인덱스는 status만 쓰는 조회나
status + created_at을 함께 쓰는 조회에 활용될 수 있다.
하지만 created_at만 조건으로 쓰는 조회에는 같은 방식으로 잘 활용되지 않을 수 있다.
선행 컬럼을 고를 때는 카디널리티도 함께 본다.
카디널리티는 값의 종류가 얼마나 다양한지를 의미한다.
보통 후보 row를 많이 줄일 수 있는 컬럼이 앞에 오면 유리하지만,
실제 인덱스 순서는 동등 조건, 범위 조건, 정렬 조건, 데이터 분포를 함께 보고 결정해야 한다.

이때 중요한 것은 EXPLAIN으로 확인하는 것이다.
EXPLAIN
SELECT id, title, writer_name, status, created_at
FROM article
WHERE status = 'PUBLISHED'
AND created_at >= '2026-02-01 00:00:00'
AND created_at < '2026-05-01 00:00:00'
ORDER BY created_at DESC
LIMIT 20;
실행 계획에서 특히 아래 항목을 먼저 본다.
| 항목 | 확인할 내용 |
|---|---|
type |
ALL이면 풀 테이블 스캔 가능성을 의심한다 |
key |
실제 선택된 인덱스가 무엇인지 확인한다 |
rows |
DB가 읽을 것으로 예상하는 row 수를 확인한다 |
Extra |
Using index, Using filesort, Using temporary 등을 확인한다 |
여기서 Using index는 “인덱스를 아예 안 쓴다”는 뜻이 아니다.
MySQL에서는 쿼리에 필요한 컬럼을 인덱스만으로 가져올 수 있을 때
Using index가 표시될 수 있다. 흔히 말하는 커버링 인덱스 상황이다.
예를 들어 아래 쿼리는 필요한 컬럼이 모두 인덱스에 포함되어 있다면
테이블 row까지 추가로 접근하지 않고 인덱스에서 값을 가져올 수 있다.
CREATE INDEX idx_article_status_created_id
ON article(status, created_at DESC, id);
SELECT id, status, created_at
FROM article
WHERE status = 'PUBLISHED'
ORDER BY created_at DESC
LIMIT 20;
반대로 인덱스에 없는 컬럼을 함께 조회하면
DB는 인덱스로 후보 row를 찾은 뒤 실제 테이블 row에 접근해야 할 수 있다.
SELECT id, title, content, status, created_at
FROM article
WHERE status = 'PUBLISHED'
ORDER BY created_at DESC
LIMIT 20;
content가 인덱스에 없다면 이 값을 읽기 위해 테이블 row 접근이 필요하다.
그렇다고 모든 조회 컬럼을 인덱스에 넣어야 한다는 뜻은 아니다.
인덱스 크기와 쓰기 비용이 커지기 때문에, 목록 화면처럼 정말 자주 호출되고
필요한 컬럼이 적은 조회에만 신중하게 검토해야 한다.
그래서 목록 조회에서는 SELECT *를 습관적으로 쓰지 않는 것이 중요하다.
화면에 필요한 컬럼만 고르면 네트워크 전송량도 줄고, 커버링 인덱스를 검토할 여지도 생긴다.
3번째 시도: LIKE 검색을 전문 검색으로 분리하기
검색어가 제목이나 본문 중간에 포함되는지를 찾아야 한다면
LIKE '%keyword%'는 기능 요구사항에는 맞지만
성능 요구사항에는 불리할 수 있다.
이때 선택지는 크게 세 가지다.
| 선택지 | 적합한 상황 | 주의할 점 |
|---|---|---|
LIKE 'keyword%' |
접두어 검색이면 충분한 경우 | 중간 단어 검색에는 맞지 않는다 |
| DB 전문 검색 인덱스 | DB 안에서 검색을 처리하고 싶은 경우 | 형태소, 언어, stopword, 정렬 품질을 확인해야 한다 |
| Elasticsearch 같은 검색 엔진 | 검색 품질, 랭킹, 다중 필드 검색이 중요한 경우 | 동기화 구조와 운영 복잡도가 늘어난다 |
MySQL에서는 FULLTEXT 인덱스와
MATCH() AGAINST() 문법을 사용할 수 있다.
CREATE FULLTEXT INDEX ft_article_title_content
ON article(title, content);
SELECT id, title, created_at
FROM article
WHERE MATCH(title, content) AGAINST ('spring boot' IN NATURAL LANGUAGE MODE)
ORDER BY created_at DESC
LIMIT 20;
Oracle을 사용한다면 Oracle Text 같은 기능을 검토할 수 있다.
검색 품질과 확장성이 더 중요하다면 Elasticsearch 같은 별도 검색 엔진을 두는 방식도 있다.
다만 검색 엔진을 붙인다고 모든 문제가 끝나는 것은 아니다.
DB와 검색 엔진 사이의 데이터 동기화, 장애 시 재처리,
검색 결과와 원본 데이터의 정합성, 색인 지연을 함께 설계해야 한다.

내가 정리한 기준은 이렇다.
단순 관리자 화면에서 가끔 쓰는 검색이면 LIKE를 유지할 수도 있다.
하지만 사용자가 자주 검색하고 데이터가 계속 늘어나는 핵심 기능이라면
일반 인덱스가 아니라 전문 검색 구조를 검토해야 한다.
정규화와 비정규화는 언제 고민해야 할까?
정규화는 데이터 중복을 줄이고 변경 정합성을 지키기 위한 설계다.
예를 들어 사용자 이름을 user 테이블에만 두고 게시글에서는
user_id만 참조하면, 사용자 이름이 바뀌어도 한 곳만 수정하면 된다.
하지만 조회 API가 매번 여러 테이블을 조인해야 하고,
그 조회가 매우 자주 호출된다면 비정규화를 검토할 수 있다.
예를 들어 게시글 목록에서 항상 작성자 이름이 필요하다고 가정한다.
SELECT a.id, a.title, u.name, a.created_at
FROM article a
JOIN users u ON a.writer_id = u.id
WHERE a.status = 'PUBLISHED'
ORDER BY a.created_at DESC
LIMIT 20;
이 조인이 성능 병목이 되고 작성자 이름 변경이 드문 요구사항이라면,
article.writer_name처럼 조회용 컬럼을 중복 저장하는 방법을 검토할 수 있다.
| 구분 | 정규화 | 비정규화 |
|---|---|---|
| 목적 | 중복 제거, 정합성 유지 | 조회 성능, 쿼리 단순화 |
| 장점 | 수정 지점이 적다 | 조인을 줄일 수 있다 |
| 단점 | 조회 시 조인이 늘 수 있다 | 데이터 불일치 가능성이 생긴다 |
| 적용 기준 | 변경이 잦고 정합성이 중요한 데이터 | 조회가 매우 많고 변경이 적은 데이터 |
비정규화는 성능 최적화 수단이지만, 동시에 정합성 비용을 만드는 선택이다.
그래서 “조인이 싫다”가 아니라 “이 조회가 병목이고,
중복 데이터의 동기화 규칙을 관리할 수 있다”는 근거가 있을 때 적용해야 한다.
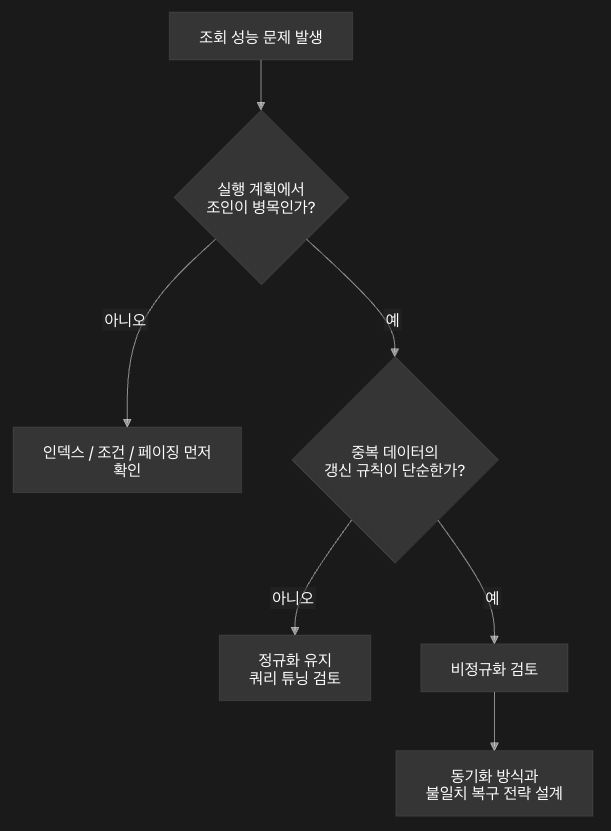
조회 범위를 줄이는 것도 성능 개선이다
인덱스를 잘 설계해도 조회 범위가 너무 넓으면
DB가 읽어야 할 데이터가 많아진다.
실무에서는 “전체 기간 조회”가 생각보다 위험하다.
사용자는 단순히 검색 버튼을 눌렀지만,
서버 입장에서는 몇 년치 데이터를 대상으로 정렬과 필터링을 수행할 수 있다.
그래서 목록 API에는 기간 조건을 기본값으로 두는 것이 도움이 된다.
SELECT id, title, status, created_at
FROM article
WHERE status = 'PUBLISHED'
AND created_at >= CURRENT_DATE - INTERVAL 3 MONTH
ORDER BY created_at DESC
LIMIT 20;
조회 범위를 제한하면 인덱스가 후보 row를 줄이기 쉬워진다.
또한 사용자도 실제로 필요한 최근 데이터부터 확인하게 된다.
물론 모든 화면에 임의로 기간 제한을 걸면 안 된다.
감사, 정산, 법적 보관 데이터처럼 전체 기간 조회가 필요한 기능은
별도 화면이나 배치성 조회로 분리하는 편이 낫다.
전체 개수를 세지 않는 것도 방법이다
페이징을 만들 때 습관적으로 전체 개수를 함께 조회하는 경우가 있다.
SELECT COUNT(*)
FROM article
WHERE status = 'PUBLISHED'
AND title LIKE '%spring%';
문제는 COUNT도 공짜가 아니라는 점이다.
특히 검색 조건이 복잡하고 필터링 대상이 많으면 DB는 개수를 구하기 위해 많은 row를 확인해야 한다.
사용자에게 반드시 “총 12,345건”이 필요한지 먼저 확인해야 한다.
필요하지 않다면 hasNext 방식으로 바꿀 수 있다.
SELECT id, title, created_at
FROM article
WHERE status = 'PUBLISHED'
ORDER BY created_at DESC
LIMIT 21;
한 페이지 크기가 20개라면 21개를 조회해서 다음 페이지 존재 여부만 판단한다.
이렇게 하면 전체 개수를 세지 않아도 된다.
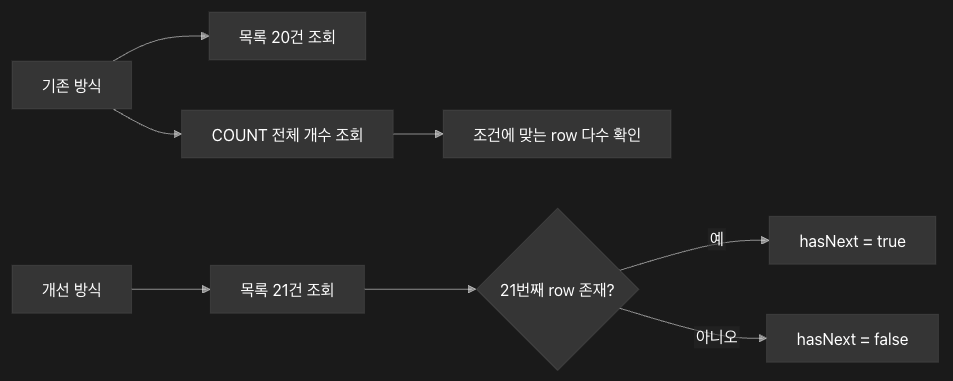
이 방식은 무한 스크롤이나 “더보기” UI와 잘 맞는다.
반대로 정확한 전체 페이지 수가 꼭 필요한 관리자 화면에서는
COUNT를 유지하되, 검색 조건과 인덱스를 더 신중하게 봐야 한다.
정확한 숫자가 중요하지 않은 화면이라면 추정값이나 캐시를 쓰는 방법도 있다.
예를 들어 통계 테이블에 일정 주기로 집계한 값을 저장하거나,
자주 반복되는 카운트 결과를 짧은 시간 동안 캐싱할 수 있다.
다만 이 경우에는 사용자에게 보여주는 숫자가
실시간 정확값이 아닐 수 있다는 점을 화면 요구사항과 맞춰야 한다.
오래된 데이터는 삭제하거나 분리 보관해야 한다
성능 문제는 쿼리만의 문제가 아닐 때가 많다.
테이블이 너무 커져서 어떤 조회를 해도 부담이 되는 상황이 있다.
예를 들어 로그인 이력, 알림 이력, API 호출 로그처럼 계속 쌓이는 데이터는
시간이 지나면 조회 빈도가 낮아진다.
이런 데이터는 보관 정책을 정하고 삭제하거나 별도 보관 테이블로 분리할 수 있다.
| 데이터 | 운영 테이블 | 보관 테이블 |
|---|---|---|
| 최근 3개월 로그인 이력 | 자주 조회 | 유지 |
| 3개월 이전 로그인 이력 | 거의 조회하지 않음 | archive 테이블 또는 별도 저장소 |
| 법적 보관 대상 | 삭제 불가 | 접근 빈도에 맞춰 분리 |

삭제나 분리는 기능팀 혼자 결정할 수 없다.
보관 기간, 감사 요건, 장애 분석 필요성, 개인정보 정책을 함께 확인해야 한다.
DB 장비 확장과 캐시는 마지막 카드가 아니다
DB 성능을 이야기하면 장비 확장이나 캐시 서버도 자주 나온다.
장비 확장은 분명 효과가 있다.
CPU, 메모리, 디스크 I/O가 부족한 상황에서는 스케일업이나
읽기 전용 복제 DB 구성이 필요할 수 있다.
캐시도 강력하다.
자주 조회되지만 자주 바뀌지 않는 데이터는 Redis 같은
별도 캐시 서버에 두면 DB 부하를 줄일 수 있다.
하지만 둘 다 쿼리와 데이터 구조를 보지 않고
바로 적용하면 문제를 늦게 발견하게 만들 수 있다.
| 방법 | 효과 | 먼저 확인할 점 |
|---|---|---|
| DB 스케일업 | CPU, 메모리, I/O 여유 증가 | 비효율 쿼리가 그대로 남는지 확인 |
| Read replica | 읽기 트래픽 분산 | 복제 지연과 읽기 정합성 확인 |
| Redis 캐시 | 반복 조회 부하 감소 | 만료 정책과 데이터 무효화 전략 확인 |
| 검색 엔진 | 검색 부하 분리 | 색인 동기화와 장애 복구 전략 확인 |
캐시는 특히 무효화 전략이 중요하다.
데이터를 수정했는데 캐시를 지우지 않으면 사용자는 오래된 값을 보게 된다.
그래서 캐시를 넣을 때는 “언제 저장할지”보다 “언제 지울지”를 먼저 설계해야 한다.
내가 기억하려는 우선순위는
쿼리 확인 → 인덱스 설계 → 데이터 분리 → 캐시 → 장비 확장이다.
인덱스도 확인하지 않은 상태에서 캐시나 장비 확장부터 적용하면,
느린 원인을 가린 채 운영 비용만 키울 수 있다.
최종 정리: DB 성능을 볼 때의 순서
내가 이번에 정리한 순서는 아래와 같다.

핵심은 인덱스를 먼저 만들기 전에 조회 패턴을 먼저 보는 것이다.
내가 기억하려는 기준은 아래와 같다.
- 풀스캔을 줄이려면
WHERE,ORDER BY,LIMIT을 함께 보고 인덱스를 설계한다. - 복합 인덱스는 컬럼 순서가 중요하며, leftmost prefix를 이해해야 한다.
LIKE '%keyword%'는 일반 인덱스보다 전문 검색 구조가 필요한 신호일 수 있다.- 인덱스에 포함된 컬럼만 조회하면 커버링 인덱스로 테이블 접근을 줄일 수 있다.
- 인덱스에 없는 컬럼까지 조회하면 후보 row를 찾은 뒤 실제 row 접근이 필요할 수 있다.
- 인덱스는 읽기 성능을 돕지만 쓰기 비용과 저장 공간 비용을 만든다.
- 비정규화는 조인을 줄일 수 있지만 데이터 불일치 비용을 만든다.
- 전체 개수가 꼭 필요하지 않다면
COUNT대신hasNext방식을 검토한다. - 오래된 데이터는 운영 테이블에서 계속 들고 있을수록 조회와 관리 비용이 커진다.
- 캐시와 장비 확장은 효과가 있지만, 비효율 쿼리를 덮는 방식으로 쓰면 안 된다.
배운 점
이번 내용을 정리하면서 DB 성능 개선은
“빠른 쿼리 하나 만들기”가 아니라는 생각이 들었다.
성능 문제는 보통 여러 층이 겹쳐서 생긴다. 조회 범위가 넓고,
검색 조건은 인덱스를 타기 어렵고, 전체 개수까지 세고,
오래된 데이터도 같은 테이블에 계속 쌓이면 느려질 수밖에 없다.
그래서 내가 실무에서 먼저 할 일은 인덱스를 추가하는 것이 아니라,
느린 API의 조회 패턴을 문장으로 설명하는 일이다.
이 API는 어떤 사용자가, 어떤 조건으로, 어느 기간의 데이터를, 몇 건이나 필요로 하는가?
이 질문에 답할 수 있어야 인덱스도 설계할 수 있고,
전문 검색도 검토할 수 있고, 캐시나 장비 확장도 근거 있게 이야기할 수 있다.
참고 링크
- MySQL 8.4 Reference Manual - How MySQL Uses Indexes
- MySQL 8.4 Reference Manual - Multiple-Column Indexes
- MySQL 8.4 Reference Manual - EXPLAIN Output Format
- MySQL 8.4 Reference Manual - Full-Text Search Functions
- MySQL 8.4 Reference Manual - InnoDB Full-Text Indexes
- Oracle Text Application Developer's Guide
- Elasticsearch Reference - Full text queries